Speech Engines for AnywhereNow
Introduction
AnywhereNow supports different Speech Providers for Text-To-Speech (TTS) and Speech Recognition (SR). By default, AnywhereNow uses the locally installed ‘MicrosoftSpeechSynthesizer’ which is always a part of AnywhereNow. Additionally, modern cloud connected speech engines with ever evolving cognitive capabilities (i.e. new words, languages and dialects are constantly being added) can be configured as a much more intelligent and natural sounding voice interaction experience. Only one additional cloud connected speech provider can be configured per UCC A Unified Contact Center, or UCC, is a queue of interactions (voice, email, IM, etc.) that are handled by Agents. Each UCC has its own settings, IVR menus and Agents. Agents can belong to one or several UCCs and can have multiple skills (competencies). A UCC can be visualized as a contact center “micro service”. Customers can utilize one UCC (e.g. a global helpdesk), a few UCC’s (e.g. for each department or regional office) or hundreds of UCC’s (e.g. for each bed at a hospital). They are interconnected and can all be managed from one central location.. If a cloud connected speech provider is configured for use but (temporarily) unavailable or mis-configured, the ‘MicrosoftSpeechSynthesizer’ will always act as a fallback.
Tip
For a graphical representation of the speech engine inter-connections see the Architecture pages on:
Various Speech Providers
The currently supported speech engines are:
-
MicrosoftSpeechSynthesizer
-
MicrosoftCognitiveServices
-
GoogleCloudTextToSpeechV1
Note
Not all messages as configured in a UCC SharePoint site can leverage the cloud connected speech providers and can only be used with the legacy 'MicrosoftSpeechSynthesizer' for text-to-speech messages. See below which message types can be played with which engine if relying on SharePoint configuration alone.
To have a full IVR flow experience based on cognitive cloud service based voices, upgrade to a License with Dialogue Studio and configure the entire IVR flow in Dialogue Studio.
MicrosoftSpeechSynthesizer
This is the Text-To-Speech provider installed as default part of AnywhereNow. This provider can be used for all text to speech operations.
Note
The MicrosoftSpeechSynthesizer is the Microsoft Server based speech SDK which has not been further developed by Microsoft since the year 2011. It supports just 26 language dialects of varying and fixed quality with one female voice per language dialect only for Text-To-Speech (TTS) as well a rudimentary, short-phrase, Speech Recognition (SR) engine for the same 26 language dialects. Learn More - Microsoft
Supported message types
- Entering Queue messages configured in the IVRQuestions list on SharePoint
- Question Queue messages configured in the IVRQuestions list on SharePoint
- Callback CallBack, an IVR menu feature for voice, enables the customer to confirm or leave an alternative phone number to be called back by an available agent during business hours. Queue messages configured in the IVRQuestions list on SharePoint
- Waiting Queue messages configured in the IVRQuestions list on SharePoint
- Quality Monitor messages configured in the QualityMonitorConfig list on SharePoint
- Various Dialer messages (played to the agent like voicemail and campaign instructions) configured in the Settings list on SharePoint
- All Dialogue Studio voice nodes (like Ask, Say, QM)
How to enable
To enable, no settings need to be added to SharePoint (as it is the default), but the settings below may be configured in the global "Settings" list for testing purposes (for example, to differentiate with the cloud speech engines mentioned further below):
UCC Settings list
| Setting | Description | Value | Remark |
|---|---|---|---|
| SpeechProvider |
The AnywhereNow technical name for the Microsoft server speech service. |
MicrosoftSpeechSynthesizer |
Optional as this is the default version |
| SpeechPreferredVoiceName |
The full AnywhereNow name for the Microsoft voice voice |
Example: |
Optional, if not specified, the global setting "CultureInfo" will be used to determine the voice. |
See image below for a list of all TTS voices available for the MicrosoftSpeechSynthesizer: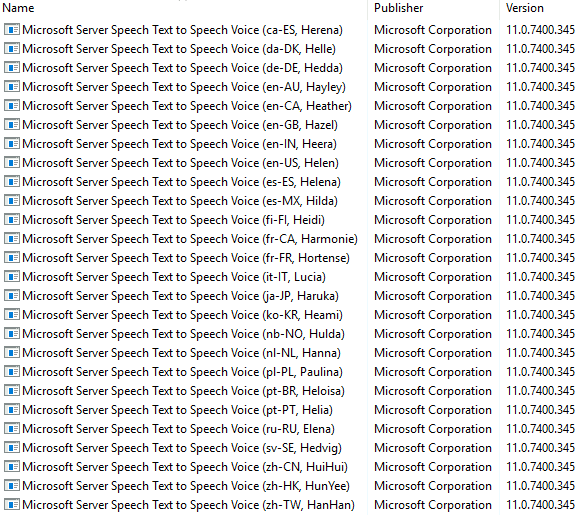
MicrosoftCognitiveServices
This speech provider uses the Azure cloud cognitive (i.e. always learning and improving) service for TTS operations. This provider offers better quality compared to the default provider. This advanced text to speech provider can only be used for specific message types:
Supported message types
-
Specific Entering Queue messages configured in the IVRQuestions list on SharePoint.
Limited to Message Closed and Holiday Message.
-
Waiting Queue messages configured in the IVRQuestions list on SharePoint
-
Callback Queue messages configured in the IVRQuestions list on SharePoint
-
All Dialogue Studio voice nodes (like Ask, Say, QM)
How to enable
To enable this speech provider you have to configure the global Settings list with settings below.
A Cognitive Services API key can be obtained through the Azure Portal. After you have added a "Cognitive Services" resource to your Azure Subscription, copy key 1 from the "Keys and Endpoint" section. Make sure to use correct endpoint addresses in the settings below when you choose to host the service in a region other than western Europe.
UCC Settings list
| Setting | Description | Value | Remark |
|---|---|---|---|
| SpeechMicrosoftCognitiveApiKey |
The api key for Microsoft Cognitive services. |
<Long String> |
Mandatory |
| SpeechMicrosoftCognitiveApiEndpoint |
The api endpoint for Microsoft Cognitive services. |
Example: https://westeurope.tts.speech.microsoft.com/cognitiveservices/v1 |
Mandatory |
| SpeechMicrosoftCognitiveApiAuthorizationEndpoint |
The authorization endpoint for Microsoft Cognitive services. |
Example: https://westeurope.api.cognitive.microsoft.com/sts/v1.0/issueToken |
Mandatory |
| SpeechProvider |
The AnywhereNow technical name for the Microsoft Cognitive cloud speech services. |
MicrosoftCognitiveServices |
Mandatory |
| SpeechPreferredVoiceName |
The full AnywhereNow name for the Microsoft voice voice |
Example: Microsoft Server Speech Text to Speech Voice (en-GB, OliverNeural) |
Optional, if not specified, the global setting "CultureInfo" will try to approximate an appropriate voice (first voice for the language retrieved from the cloud provider). |
Note
The highly advanced, and even customizable, Microsoft Cognitive Services cloud Text-to-Speech is subject to additional costs, these may even vary per selected voice and quality, and are billed on the customer's Azure subscription. For rates see https://azure.microsoft.com/en-us/pricing/details/cognitive-services/speech-services/.
GoogleCloudTextToSpeech
Google Cloud Text to Speech service provides the most comprehensive set of voices. For a complete overview of all voices check https://cloud.google.com/text-to-speech/docs/voices. This advanced text to speech provider can only be used for specific message types:
Supported message types
-
Specific Entering Queue messages configured in the IVRQuestions list on SharePoint.
Limited to Message Closed and Holiday Message.
-
Waiting Queue messages configured in the IVRQuestions list on SharePoint
-
Callback Queue messages configured in the IVRQuestions list on SharePoint
-
All Dialogue Studio voice nodes (like Ask, Say, QM)
How to enable
To enable this speech provider you have to configure two lists, global Settings and the PluginSettings.
The PluginSettings list will contain the Credentials JSON of the Google service.
UCC Settings List
| Setting | Description | Value | Remark |
|---|---|---|---|
| SpeechProvider |
The AnywhereNow technical name for the Google Cognitive cloud speech services. |
GoogleCloudTextToSpeechV1 |
Mandatory |
| SpeechPreferredVoiceName |
The full AnywhereNow name for the Google cloud voice |
Example: nl-NL-Wavenet-C |
Optional, if not specified, the global setting "CultureInfo" will try to approximate an appropriate voice (first voice for the language retrieved from the cloud provider). |
PluginSettings List
| Setting | Scope | Value | Remark |
|---|---|---|---|
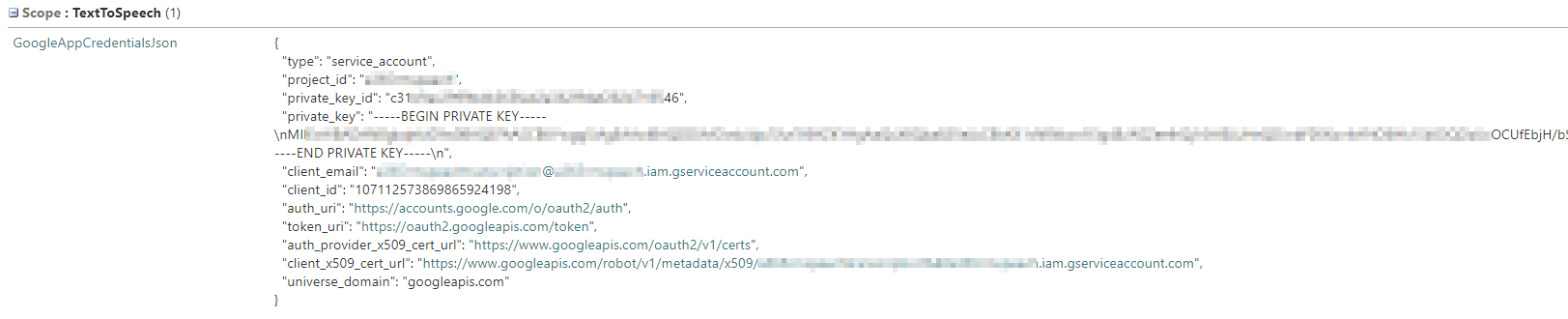
| GoogleAppCredentialsJson | TextToSpeech |
Json generation in Google Cloud. Example: |
Mandatory |
Note
The highly advanced, and even customizable, Google Cloud Text-to-Speech is subject to additional costs, these may even vary per selected voice and quality, and are billed on the customers Google Cloud subscription. For rates see: https://cloud.google.com/text-to-speech/pricing
Configuring Voice Selection in UCC
By default, the UCC will select the voice which name matches the value of the setting SpeechPreferredVoiceName (a setting in the global "Settings" list of the UCC, and should match the "Voicename" of the corresponding text to speech provider).
If there is no exact match, it will try to select a voice based on the value of the setting "CultureInfo". If there are multiple matching voices (for say the CultureInfo en-AU), the first voice that matches the criteria will be selected from the cloud speech provider.
When a speech provider can't initialize or is misconfigured the MicrosoftSpeechSythesizer will be used as fallback.
Configuring Voice Selection Dialogue Studio
Via Dialogue Studio it is possible to configure the voice in three ways:
-
Default (UCC Configured); see above "Configuring Voice Selection in UCC".
-
Custom Voice; configure the Culture and Gender, and the UCC will select a voice of the configured text to speech provider matching the criteria.
Note
Gender selection is available only with Microsoft Cognitive Services and Google Cloud Text-to-Speech V1. It is not available for Microsoft Speech Synthesizer, as it supports only one gender per language.
-
SSML; this makes it possible to select multiple voices for each individual node in your flow (useful for multilingual messages).